
1. Contexto del problema
Dentro del contexto del análisis de cliente, he experimentado que a menudo las señales cualitativas que provienen de entornos que proporcionan métricas de vanidad, no se implementan de forma estratégica dentro de una investigación concienzuda del cliente con el objetivo de entender qué es lo que este piensa con respecto a nuestro producto o servicio.
El problema es que gran parte de la fricción en la decisión de compra no es explícita. No es información que se encuentre en dashboards, ni puedas extraer de conversiones o de entrevistas estructuradas o encuestas, porque siempre hay un bias: dependerá del contexto del cliente en el momento de responder.
No obstante, en la interacción comunitaria en Social Media aparecen conversaciones reales sobre nuestros productos y servicios y, además, actúan como pruebas de calidad que en SEO y GEO se utilizan para validar que el contenido es útil y la marca confiable.
El mejor feedback que recibimos proviene de entornos comunitarios dentro de conversaciones que buscan resolver dudas para tomar decisiones. En foros, comentarios y redes sociales se abordan experiencias individuales o puntos de vista que pueden anticipar fricciones relevantes.
El problema es que es necesario estructurar e interpretar esas señales para detectar las fricciones en la decisión de nuestro público objetivo.
2. Qué señal queremos capturar
Se requiere un sistema que no solo busque si la opinión es positiva o negativa, sino que nos proporcione una idea de qué señales de fricción existen en la decisión.
- ¿Por qué duda?
- ¿Qué incertidumbre tiene?
- ¿Confía en nosotros?
- ¿Qué dicen los clientes que han utilizado nuestros productos o servicios?
Esta información actúa en el momento en donde el cliente se encuentra en el Middle Funnel. Ya le hemos impactado, pero no le hemos convencido.
Y eso es lo que queremos detectar: las señales de decisión frente a las señales de percepción de las referencias.
3. Enfoque del sistema
Existen herramientas de pago para analizar el sentimiento de tu marca. Utilizan Inteligencia Artificial (IA) y Procesamiento del Lenguaje Natural (PLN) para clasificar textos en positivos, negativos o neutros, permitiendo medir la opinión sobre marcas o productos. Destacan opciones como YouScan para IA avanzada, SentiSum para atención al cliente y opciones gratuitas como Hootsuite.
Sin embargo, en este LAB el objetivo es probar una solución personalizada para obtener la data necesaria.
Así que he planteado este sistema que no intenta ser perfecto, sino útil para toma de decisiones. Para ello he tomado la fricción que he detectado en un SaaS Edtech que vende formación para salidas profesionales tech.
4. Arquitectura simplificada
He desarrollado este script en Python en tres capas lógicas:
Texto
Comentarios reales recogidos manualmente.
Clasificación
Sentimiento y tema.
Interpretación
Lectura humana y estratégica.
Como siempre, para trabajar con un MVP hay que aceptar trade-offs, de los cuales hablaré luego. Pero he centrado la arquitectura de la herramienta de esta forma:
- Texto bruto: comentarios reales de Reddit que explico en el post de estrategia.
- Clasificación automática: sentimiento + tema.
- Lectura estratégica: humana.
Input manual: para obtener un script MVP. Si funciona, se valida escalar. Si requiere más trabajo, se puede adecuar más fácilmente.
Preprocesado: eliminación de ruido —anuncios y bloques no relevantes— y normalización básica para organizar los datos.
Análisis: modelo de sentimiento con pysentimiento y clasificación temática basada en keywords.
Output: dashboard exploratorio, dataset estructurado en CSV / Excel y base para reporting externo.
5. Procesamiento y limpieza de datos
Aquí el mayor reto representa limpiar los datos antes de procesarlos, aportarles estructura, criterio y sentido para el análisis que buscamos. Como los datos provienen de Reddit, antes de su análisis es necesario eliminar el ruido:
- Publicidad (“Patrocinado”).
- Metadatos visuales.
- Fragmentos incompletos.
- Texto irrelevante.
Se implementa eliminación de bloques publicitarios completos, filtros por longitud mínima, detección de patrones de ruido y limpieza estructural del texto.
6. Modelo de análisis: qué mide y qué no
He utilizado un modelo de sentimiento en español, pysentimiento, que proporciona outputs:
- Positivo (POS)
- Negativo (NEG)
- Neutral (NEU)
El modelo está hecho para medir emoción lingüística, no percepción de negocio. Esto último depende del criterio profesional.
Importante, el modelo:
- No entiende contexto de negocio.
- No detecta intención real del usuario.
- No diferencia entre duda, objeción o simple curiosidad.
Esto implica que un comentario como:
“Me interesa, pero no sé si luego encuentras trabajo”
puede ser clasificado como NEU, cuando en realidad representa una fricción clara en la decisión.
Aquí es donde entra el concepto clave: emoción lingüística vs percepción de negocio. El modelo clasifica texto, pero como ya comenté, la interpretación estratégica la hace la persona que analiza.
7. Estructura de outputs
El sistema genera tres niveles de output, pensados para distintos usos:
Nivel 1
Exploración
Dashboard en Streamlit, visualización de distribución de sentimiento y gráficos por tema.
Nivel 2
Dataset
Usuario, comentario, sentimiento, confianza y tema. Pensado para ser legible por humanos, no solo por sistemas.
Nivel 3
Export
CSV, Excel, Markdown e input para LLMs como GPT, Gemini o Claude.
Esto permite utilizar el resultado como base para reporting manual, generación automática de presentaciones y cruce con otros análisis.
8. Cómo leer las señales: uso en marketing
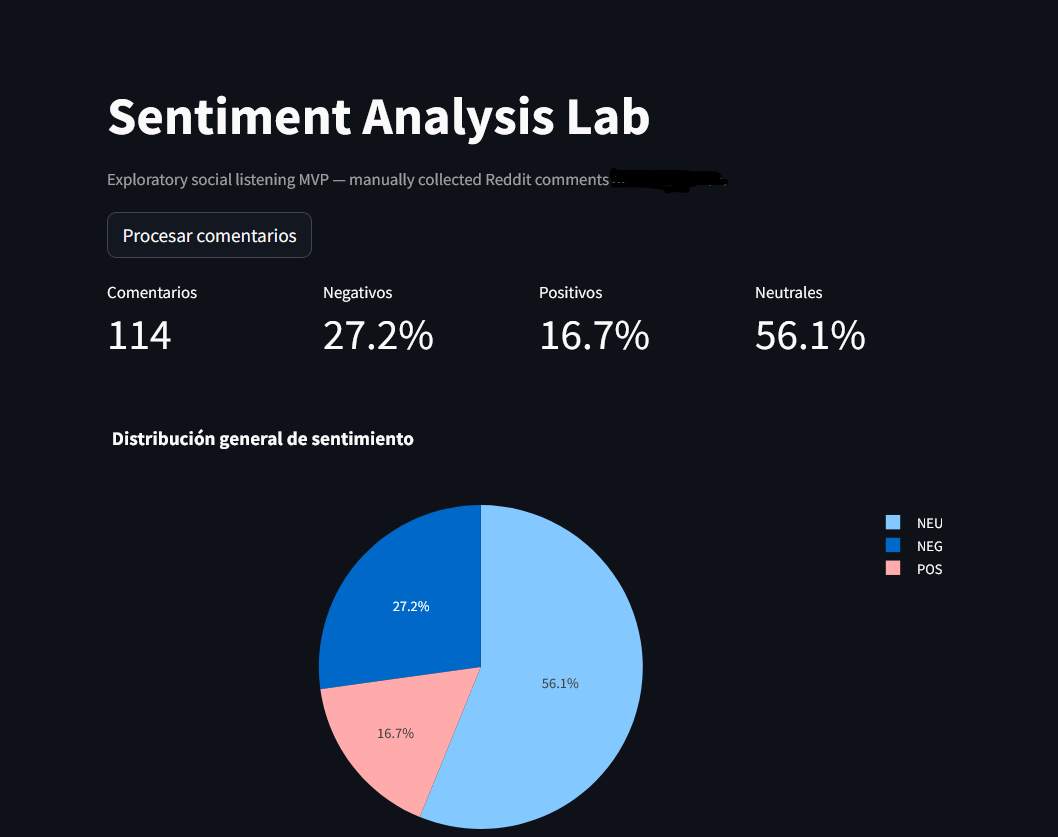
El error más común sería mirar únicamente el porcentaje de negativos.
El valor está en el cruce de sentimiento + tema.
| Combinación | Lectura posible |
|---|---|
| NEU + empleabilidad | Duda sobre retorno. |
| NEU + precio | Incertidumbre de valor. |
| NEG + ventas | Rechazo a presión comercial. |
| POS + experiencia | Prueba social. |
Esto permite identificar dónde se genera la fricción, qué objeciones existen antes de la conversión y qué mensajes necesitan ser reforzados.
Aquí no se toma la decisión, pero se identifica dónde se rompe.
Ejemplo aplicado: cómo usar este sistema
Para aterrizar el uso del sistema, planteo un escenario típico: una empresa SaaS en Edtech tiene buen volumen de captación, pero no consigue sostener el crecimiento ni aumentar el LTV mediante recompra o upsell.
Antes de seguir invirtiendo en captación, la pregunta no es cuánto tráfico entra, sino: ¿qué está pasando en la decisión después del primer impacto?
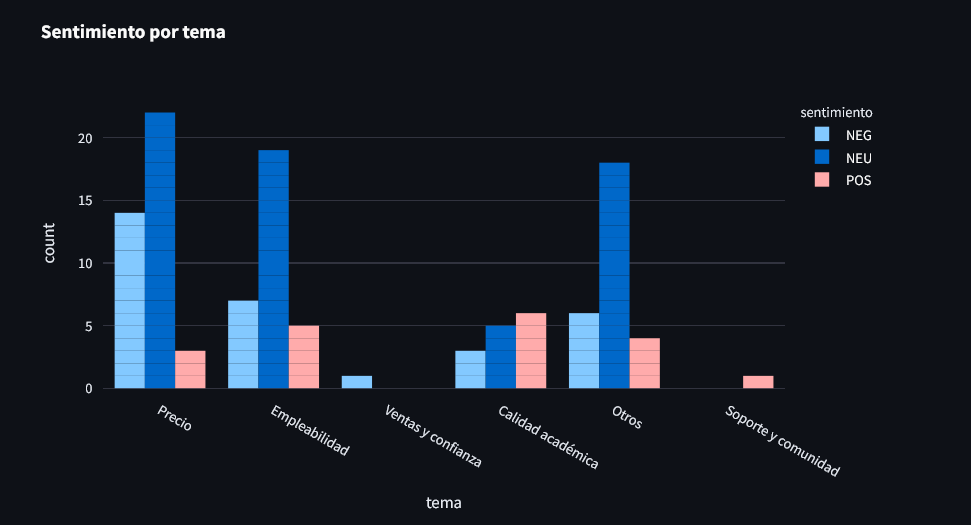
Al analizar conversaciones en entornos comunitarios como Reddit, aparecen patrones como un alto volumen de comentarios NEU en empleabilidad, comentarios NEG en precio y ventas, y comentarios POS en contenido puntual o experiencia aislada.
Esta información que proporciona este programa en este ejemplo indica que la decisión no se está sosteniendo.
Por ejemplo, NEU + empleabilidad puede indicar que el usuario no tiene certeza de retorno. NEG + ventas puede indicar rechazo a presión comercial o expectativa mal gestionada. POS + contenido puede señalar valor percibido en partes, pero no necesariamente en el conjunto.
No estamos midiendo satisfacción, el programa no busca eso. Su objetivo es detectar incertidumbre, falta de confianza y desalineación entre expectativa y experiencia.
Esto sirve para empezar a plantearse preguntas como: ¿por qué alguien interesado no termina de confiar?, ¿qué objeción aparece antes de la compra o recompra?, ¿qué parte del discurso no está alineada con la experiencia real?
Toda esta información ayuda a responder dónde se rompe la decisión del usuario antes de convertir o repetir, desde un contexto real de decisión basado en el lenguaje del usuario en un entorno natural.
Porque muchas veces el problema no está en generar demanda, sino en sostener la decisión, eliminar fricciones y alinear expectativa con realidad. Y eso no se ve en dashboards de adquisición, sino en analizar cómo habla la gente cuando no le estás vendiendo.
9. Trade-offs
Como comenté antes, como todo MVP, el sistema se ha construido aceptando decisiones conscientes:
| Decisión | Se elige ahora | Se deja para después |
|---|---|---|
| Feed de datos | Input manual | Scraping automático |
| Clasificación temática | Keywords | NLP avanzado |
| Modelo | Modelo preentrenado | Fine-tuning |
| Temporalidad | Análisis puntual | Sistema continuo |
Con estas decisiones se gana velocidad de implementación, control sobre el dato, facilidad de ajuste y claridad en el output.
Pero también se pierde escalabilidad, precisión semántica, automatización y profundidad analítica.
10. Qué no se ha hecho y por qué
No se han implementado:
- Scraping automatizado de Reddit o foros.
- Normalización avanzada mediante embeddings.
- Clustering semántico.
- Detección automática de patrones de objeción.
- Sistema continuo de ingesta de datos.
Como ya he explicado, el objetivo no era escalar el sistema sino validar que la señal existe y es útil para la toma de decisiones.
11. Escalabilidad teórica
Si el sistema demuestra valor y vamos a utilizarla a menudo, la evolución natural sería:
| Fase | Qué implica | Objetivo |
|---|---|---|
| Fase 1 actual | Input manual, análisis puntual y validación de señal. | Comprobar utilidad. |
| Fase 2 | Scraping automatizado, Reddit API / web scraping y almacenamiento estructurado. | Aumentar volumen. |
| Fase 3 | Clustering semántico, agrupación por intención y patrones de objeción. | Mejorar lectura. |
| Fase 4 | Sistema continuo de ingesta, dashboard vivo e integración con otros datos de negocio. | Operativizar señal. |
12. Arquitectura con agentes
A nivel teórico, este sistema puede evolucionar hacia una arquitectura basada en agentes:
| Agente | Función | Resultado esperado |
|---|---|---|
| Agente de feed | Scraping de Reddit / foros y recogida de datos. | Entrada continua de información. |
| Agente de procesamiento | Limpieza, normalización y deduplicación. | Dato utilizable. |
| Agente de análisis | Clasificación de sentimiento y clasificación temática. | Señales estructuradas. |
| Agente de interpretación | Detección de patrones y síntesis de insights. | Lectura estratégica preliminar. |
| Agente de reporting | Generación de informes y creación de presentaciones. | Output accionable. |
Este flujo no está implementado en este LAB. No obstante, representa una posible evolución del sistema. La arquitectura propuesta no se basa en scraping indiscriminado, sino en la orquestación de fuentes de datos según su nivel de acceso: APIs oficiales, datos propios y captura manual estructurada.
La automatización del «feed» de comentarios no es solo un problema técnico, sino también de cumplimiento y gobernanza del dato.
13. Limitaciones del sistema
- Dataset reducido.
- No representativo estadísticamente.
- Pérdida de contexto conversacional.
- Modelo limitado a clasificación básica.
Este sistema no sustituye una investigación completa, pero sirve como herramienta exploratoria para poder aportar perspectiva junto a otras señales.
14. Aprendizajes
El mayor desafío hoy en día no es tanto la capacidad de analizar información, sino saber cómo estructurar esos datos para que realmente tengan sentido. Al final, hay que entender que un entorno “neutral” no implica que todo fluya sin fricción, ya que los problemas suelen aparecer mucho antes de que se vean reflejados en un KPI.
En este escenario, la IA es una herramienta increíble para acelerar el proceso, pero es fundamental no olvidar que, aunque procese rápido, no puede sustituir la capacidad humana para interpretar lo que esos números nos están diciendo realmente.
15. Conexión a Estrategia
Este sistema no decide por ti, pero te enseña dónde se está rompiendo la confianza de tus usuarios. La tecnología nos da la señal; la lectura estratégica de esos datos la desarrollo en la sección de Estrategia.
FAQ
¿Este sistema sustituye una investigación de cliente?
No. Este sistema no sustituye una investigación completa ni representa una muestra estadística. Su función es exploratoria: ayuda a estructurar conversaciones cualitativas dispersas para detectar señales tempranas de fricción, dudas o desalineación entre expectativa y experiencia.